
Categorizing images in Python
This is a repost of a piece I wrote on Medium.
During the last NorthSec CTF in Montreal, there was a fun little challenge related to “computer vision”. I put that in quotes, because we ended up with a quick and dirty solution that had very little to do with computer vision. Here’s the description of the challenge…
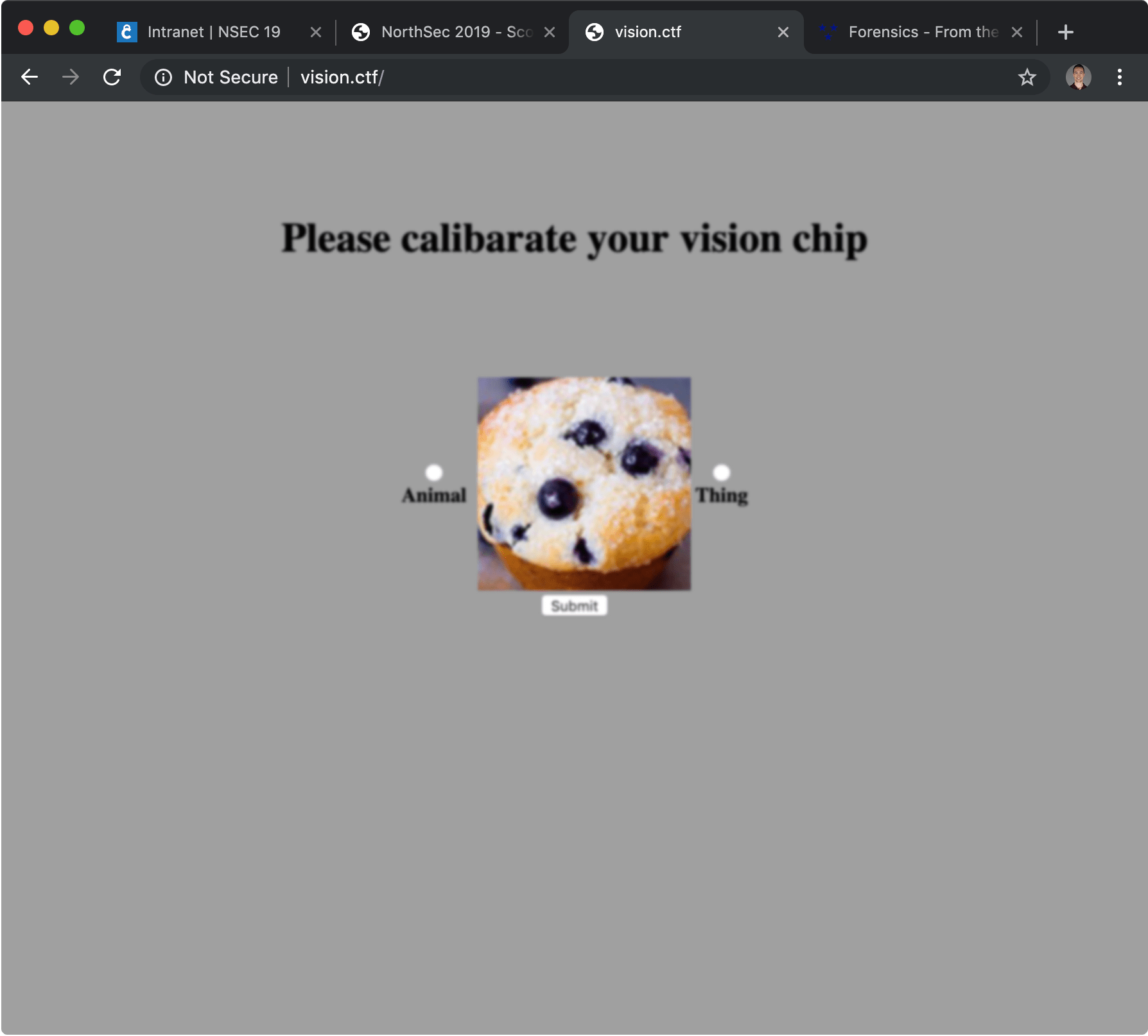
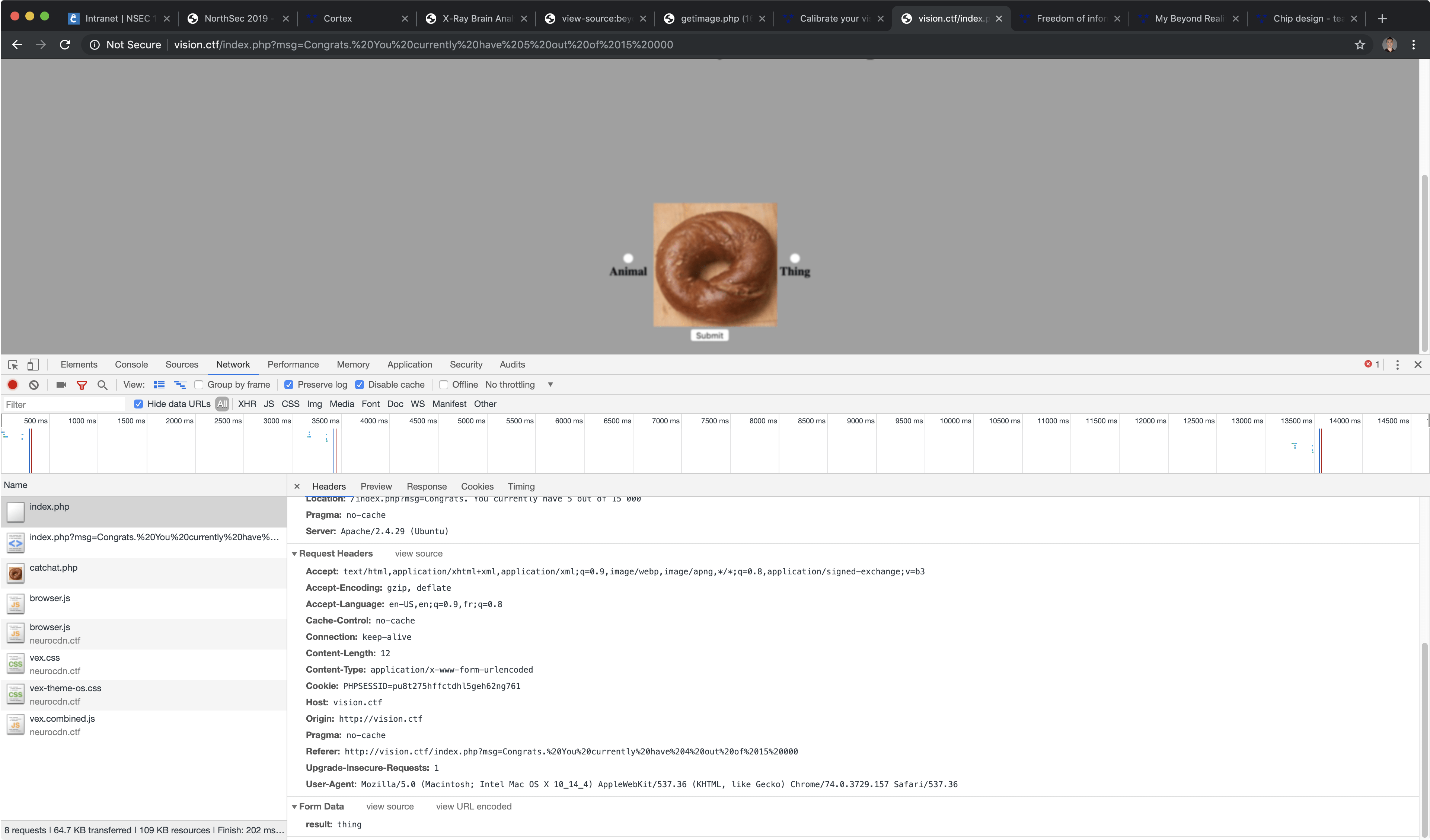
When you followed the link, you ended up on a page with a random image in the middle, along with two choices you could select to categorize the image: Animal or Thing. The page was blurry, due to a CSS filter on the whole document. This was in line to the neuro-chip implant theme of the CTF and was not a hindrance in solving the challenge.
A bit of recon…
First, we had to understand how the challenge worked, so we manually selected an answer and submitted the form, to see what it did…
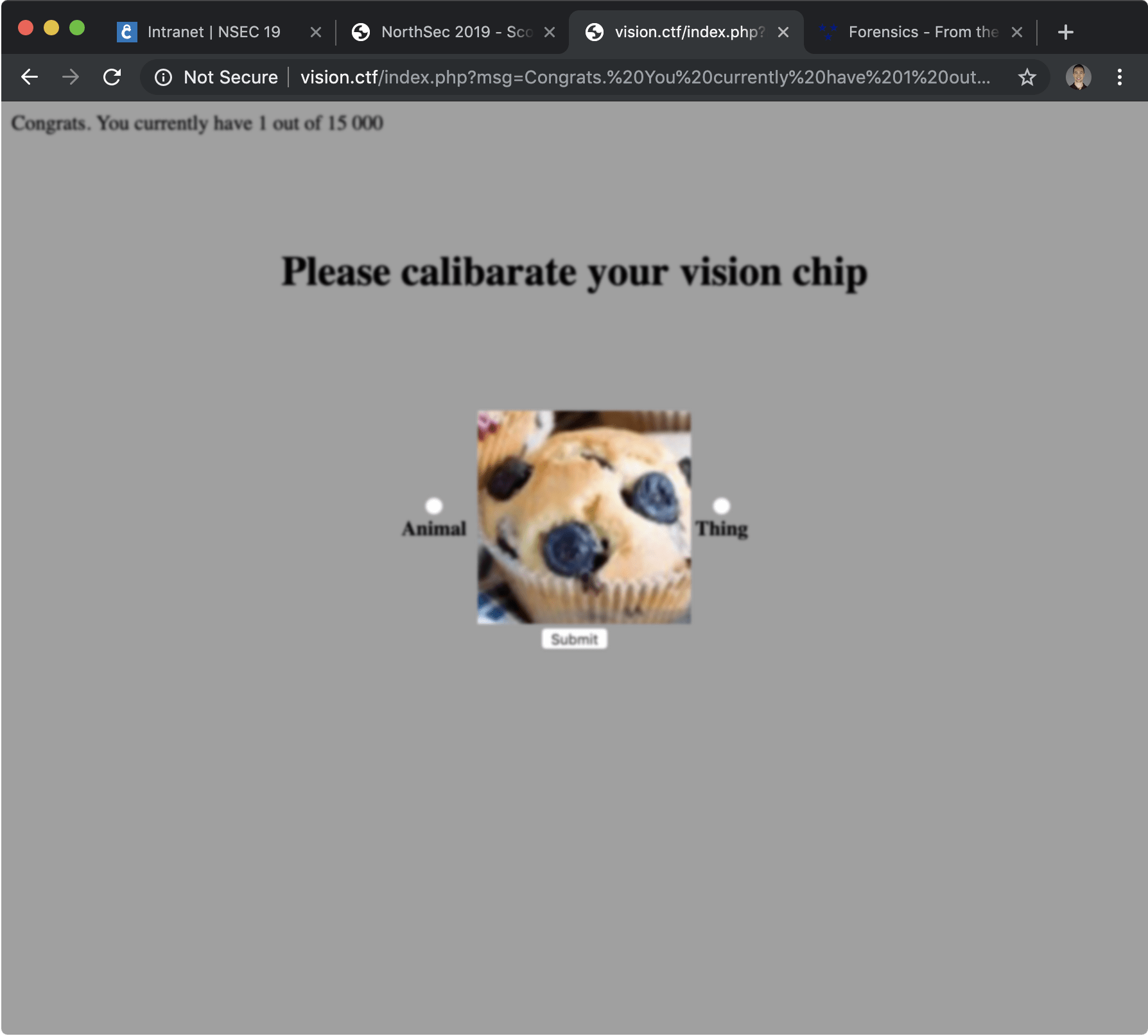
Notice at the top left of the page, a message with a score was added, telling us how many attempts we had to get right to get our hand on the flag. Obviously, we didn’t want to do more than a few manually, we’re lazy hackers after all.
Another thing we wanted to know in this recon phase, was what happened if we submitted a wrong answer. The result? They sent us back to square one. That meant, we had to guess 15 000 images right, without making a single mistake… yikes!
Next recon step was to look at the source code of the page, to see how the images were fetched.
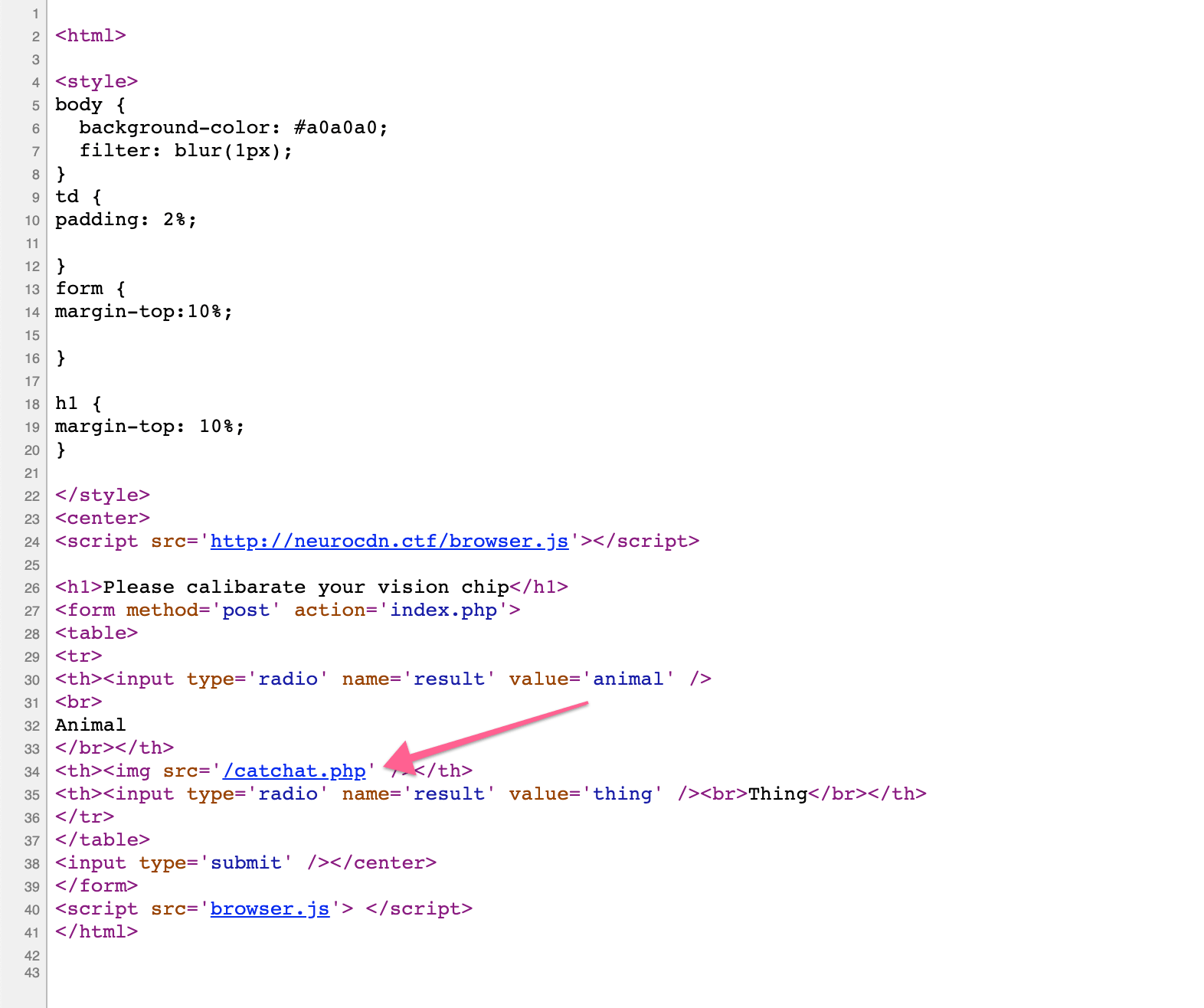
As you can see in the source code (apart from the table layout!), is that a PHP script was used to generate the image. Nothing changed in the source from one request to the next, the files were generated dynamically by the backend.
Our follow-up question was, how did they keep track of which image is shown to compare against our answer? Our guess was that it was stored in the session, and each time we submitted the form, it knew the last image that was shown to us. So if we made a request to /catchat.php in another browser tab, we were at risk of changing the answer we needed to POST.
As far as we could tell, the only identifying information we had was our session cookie, so we’d need to keep that value for later.

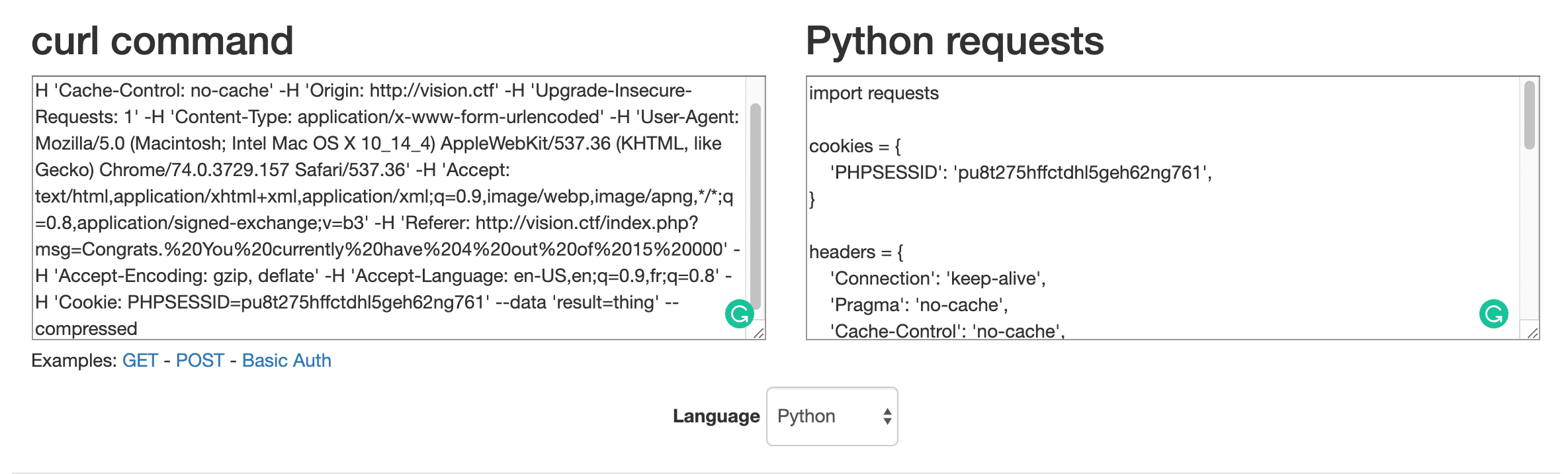
The last thing we needed before we could get started, was to peek at how the request was sent to the server. We’d then have enough information to replicate the communication between the browser and the server in a Python script of our own.
Not bad, just a plain and simple form POST request. With this knowledge, we had enough to get scripting. Just before we closed the browser to open our favorite code editor, we copied the POST request as a cURL command (in the right-click menu), and used this nifty online tool to convert the request to a Python script using the requests library. That would be the base of our submission script later on.
The vision script
Now, we had everything we needed to start coding. One thing I didn’t mention, is that while testing the form manually, we noticed that there was a pretty limited set of images, like a couple dozen at the most. Definetly not enough to train a machine learning algorithm, so we figured that’s not how they wanted us to solve the challenge.
We instead decided to brute-force the dataset and help the script categorize the images when it was not able to do so automatically. The plan was to make a script that would fetch the image, fingerprint it with MD5, prompt us for the right answer and then store that in a database. It didn’t take long before we hacked together a script that would do just that.
import hashlib
import tempfile
import click
import requests
CHALLENGE_URL = "http://vision.ctf/index.php"
IMG_URL = "http://vision.ctf/catchat.php"
DB_FILE = "db.ini"
def main():
SET = set()
while True:
r = requests.get(IMG_URL)
with tempfile.NamedTemporaryFile() as f:
f.write(r.content)
f.seek(0)
d = hashlib.md5()
d.update(r.content)
hash = d.hexdigest()
print_image(f.name)
if hash in SET:
continue
SET.add(hash)
value = 0
while value not in [1, 2]:
value = click.prompt("\nPlease enter 1 for animal, 2 for thing", type=int)
with open(DB_FILE, 'a') as db:
db.write(f"{hash}:{value}\n")
def print_image(image_file_name=None, data=None):
# Not shown here, but does basically what imgcat does: print an image to the terminal
if __name__ == '__main__':
main()
The script downloads an image, generates a hash with the content, prints the image to the terminal, prompts the user for an answer and then stores that answer in a makeshift database. The plan was to slowly categorize the images by hand until our database had an answer for every image.
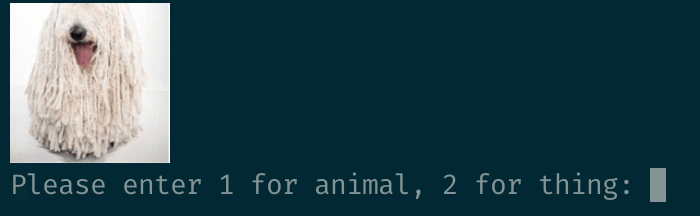
As you answer, it fills up a flat file with image hashes and the associated answer, just like this:
f26d00bb19e3c79d0a4ff85aed50dc96:2
07580c9a6f044fec2cd74e9b79bd6d6f:2
90d17252fe7fa717b885825364c85714:2
83b713786721bf8ba076c5c3ee38220f:2
1c46f966b259cad40fba80cd8691089a:2
...
The trouble was, our script never exited the infinite loop. It just kept adding more and more hashes to the database, even though we started to see the same images come up repeatedly in the terminal, something just wasn’t right…

Why did we get the same image twice?! 🤔
To understand why, we had to download a few images locally and compare them with a diff tool…
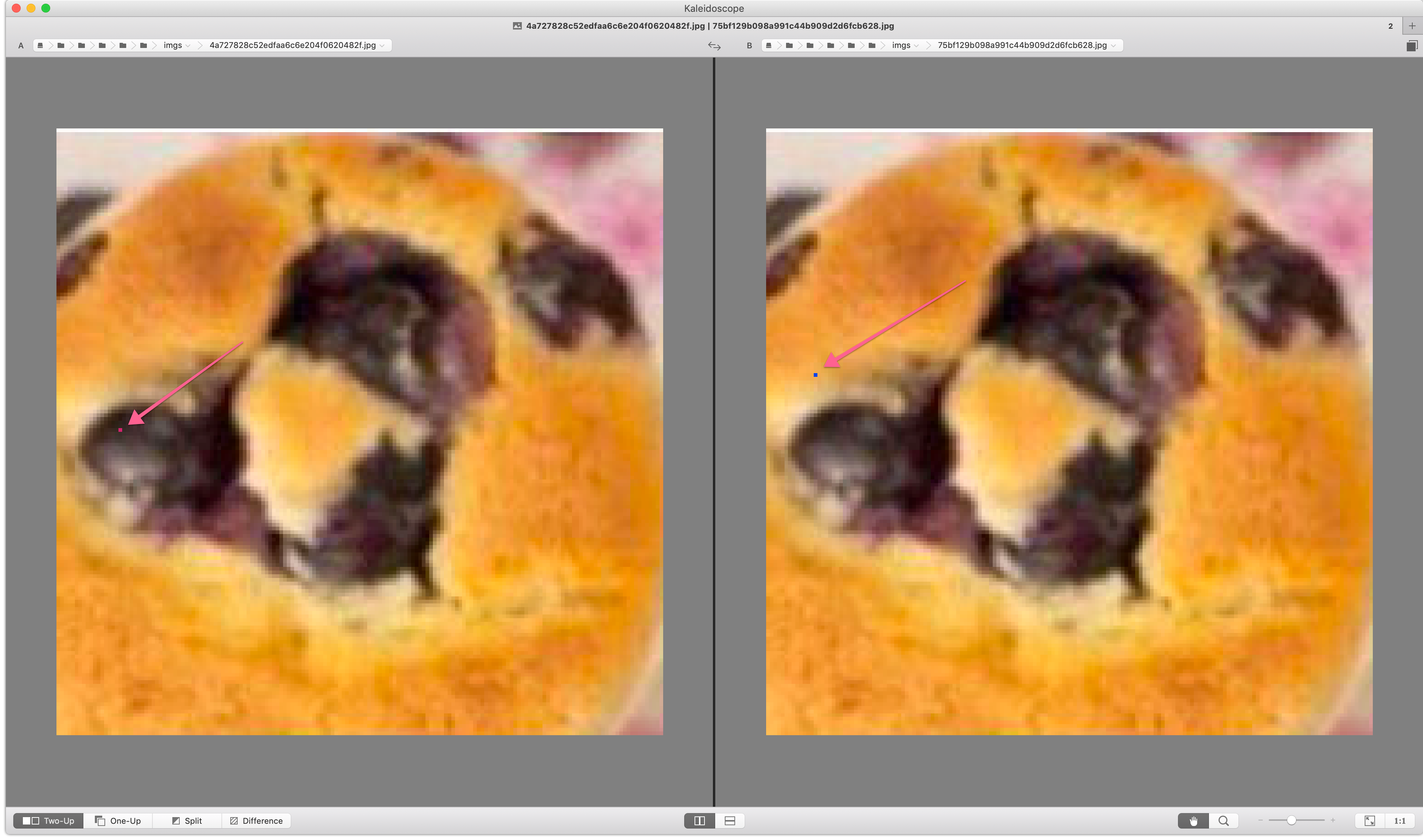
As you can see in the screenshot, the server was inserting a random colored pixel somewhere in the image, to make sure we couldn’t hash the pictured as easily. We could be shown what looked like an image we have seen before, but the checksum would be completely different. It was back to the drawing board…

We brainstormed a few solutions to that hiccup. We basically wanted a checksum algorithm we could use to fingerprint files quickly, but that didn’t have one of the properties of most hashing algorithm: the fact that any small change in the input value results in a completely different output value.
One solution we explored was converting the PNG image to a bitmap, hashing each of the 166 lines individually and comparing the matrices with a ~2% threshold, because two of the rows could end up being different.
As we painfully updated the script, we stumbled on a package that seemed promising. It basically does image hashing, but way better than what we intended to do. The hashing strategy that was particularly interesting to us was the average hash, that could be used to fingerprint images and compare them in a way that ignores minute differences (a.k.a. high frequencies).
In pictures, high frequencies give you detail, while low frequencies give you structure. Think of pixel level details and colors versus overall shapes and luminosity.
The trick behind the algorithm is simply to scale down the image enough that you lose those high frequencies, e.g. by scaling it down to an 8x8 square and converting it to grayscale. It can then compute a Hamming distance between two images to tell you how similar they are. A distance of 5 or less, it’s probably the same image, save a few minor artefacts. A distance of 10 or more, the images are probably very different.
With that new weapon in our arsenal, we updated our script!
import base64
import os
import tempfile
import click
import imagehash
import requests
from PIL import Image
from imagehash import hex_to_hash
CHALLENGE_URL = "http://vision.ctf/index.php"
IMG_URL = "http://vision.ctf/catchat.php"
DB_FILE = "db.ini"
def main():
hashes = []
with open(DB_FILE) as db:
for l in db.readlines():
hashes.append(hex_to_hash(l.split(':')[0]))
while True:
r = requests.get(IMG_URL)
with tempfile.NamedTemporaryFile() as f:
f.write(r.content)
hash = imagehash.average_hash(Image.open(f.name))
if is_already_in_db(hash, hashes):
continue
hashes.append(hash)
value = 0
while value not in [1, 2]:
value = click.prompt("\nPlease enter 1 for animal, 2 for thing", type=int)
with open(DB_FILE, 'a') as db:
db.write(f"{hash}:{value}\n")
The distance comparison happens in the is_already_in_db() function:
def is_already_in_db(hash, hashes):
for h in hashes:
if hash - h < 5:
return True
return False
We knew our new strategy worked when the script started classifying images all by itself, never asking for user input 👌
Here’s what our database looked like after letting the script run for a while to make sure it prompted us for all the possible images. All the hashes, and all the associated answers.
bf1f9f8080808080:1
ffffff763e188081:2
ff05c09316c7ffff:2
7c3f1d190707073f:1
ffff8100080d85c7:1
...
With that database, we could write a final script to submit our answers.
Our “solver” script
We started our solver script with the Python code that was generated from the POST request. This was to ensure we had all the headers we needed and the PHP session cookie.
cookies = {
'PHPSESSID': 'pu8t275hffctdhl5geh62ng761',
}
headers = {
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Origin': 'http://vision.ctf',
'Upgrade-Insecure-Requests': '1',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'BrainChip',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Referer': 'http://vision.ctf/index.php',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.9,fr;q=0.8',
}
We started by loading our database in memory, then looped through the images from 1 to 14995, thinking we might want to do the last few manually, just so we wouldn’t miss the flag.
The rest of our script looked pretty similar to the vision script: download the image, hash it, compare it to the hashes we have in our database and when a match is found, submit the answer for that image.
Because we’re a paranoid bunch, we decided to leave the code that would prompt us for an answer, in case a random image was slipped in the lot by an evil challenge maker. We also decided to leave a bunch of debug statements in, just in case we had to figure out a problem.
def main():
hash_result = []
with open(DB_FILE) as db:
for l in db.readlines():
result_hash, image_type = l.split(':')
hash_result.append((imagehash.hex_to_hash(result_hash), image_type,))
for i in range(1, 14995):
r = requests.get(IMG_URL, headers=headers, cookies=cookies)
print(i)
with tempfile.NamedTemporaryFile() as f:
f.write(r.content)
hash = imagehash.average_hash(Image.open(f.name))
result = None
for result_hash, image_type in hash_result:
if hash - result_hash < 5:
result = int(image_type)
break
while result not in [1, 2]:
print(f"hash: {hash}")
print(f.name)
print_image(f.name)
result = click.prompt("\nPlease enter 1 for animal, 2 for thing", type=int)
data = {
'result': 'animal' if result == 1 else 'thing'
}
print(data)
response = requests.post(CHALLENGE_URL, headers=headers, cookies=cookies, data=data)
if response.ok:
print('ok!')
Conclusion
We let the script run for a while, gingerly submitted the last few answers manually and finally got our flag! 🍾
It was a fun coding challenge, and while our code was arguably a lot more complicated than other write-ups I saw, we learned a ton about the different ways you can compare an image.
It was really satisfying to see the script classifying images all by itself when we finally got our image hashing right.
By the way, if you found a typo, please fork and edit this post. Thank you so much!